Wikimarks
Wikimark Collections
In addition to the raw conversions described above, we also provide several Wikimarks extracted from these conversions:
the
benchmarksdataset provides Wikimarks for passage retrieval, entity retrieval, query-specific clustering, and entity linking, extracted from the page subsets described below.the
unprocessedAllButBenchmarkdataset provides all pages except for the set included inbenchmarksand is intended to be used for training of systems to be evaluated usingbenchmarks.the
paragraphCorpusdataset is a corpus of paragraphs from articles to be used for passage retrieval evaluation.
These datasets are provided in JSONL or CBOR formats.
Page Subsets
The benchmarks described above are constructed from the following subset of Wikipedia pages from each of the provided Wikipedias:
- Vital-articles:
A set of important articles that the Wikipedia community identified. The community strives to provide these articles for all languages. We obtain the set of “vital” articles via Wikidata, then filter the processed articles by Wikidata QID.
trec-car-filterPredicate:qid-set-from-file "./vital-articles.qids"- Good-articles:
A Wikipedia committee defines a set of good articles that are well-written, contain factually accurate and verifiable information and are of broad importance. Such pages are identified either as template “GA” or “good article”, which our pipeline is configured to expose as page tag “Good article”.
trec-car-filterPredicate:has-page-tag ["Good article"]- US-history:
A set of pages in categories that contain the words “United” “States” “history”, such as “History of the United States” or “United States history timelines”.
trec-car-filterPredicate:(category-contains "history" & category-contains "united" & category-contains "states")- Horseshoe-crab:
The single Wikipedia page on horseshoe crabs used in the example above. It is identified by its Wikidata QID.
trec-car-filterPredicate:qid-in-set ["Q1329239"]
Additionally, we provide subsets used in the TREC Complex Answer Retrieval Track for backwards compatibility.
Subset Statistics
| en | simple | ja | |
|---|---|---|---|
| vital-articles.test | 521 | 461 | 503 |
| vital-articles.train | 528 | 471 | 539 |
| good-articles.test | 17,086 | 1 | 809 |
| good-articles.train | 17,361 | 2 | 838 |
| US-history.test | 4,232 | 9 | -- |
| US-history.train | 4,284 | 13 | -- |
| horseshoe-crab.train | 1 | 1 | -- |
| benchmarkY1.test | 131 | 44 | 71 |
| benchmarkY1.train | 117 | 42 | 81 |
| car-train-large.train | 884,709 | 17,335 | 246,649 |
| test200.test | -- | 1 | 42 |
| test200.train | 188 | 12 | 44 |
Wikimarks
We provide a methodology for deriving Wikimarks for four common information retrieval tasks:
- passage retrieval: retrieval of relevant text passages for a keyword query
- entity retrieval: retrieval of relevant entities (defined to be Wikipedia pages) for a keyword query
- query-specific clustering: sub-topic clustering of passages for a keyword query
- query-specific entity-linking: annotation of query-relevant entity links in relevant passages
Wikimarks are created from a subset of Wikipedia pages, such as lists of Wikidata QIDs or category memberships. The page subset is separated into a test set and five train folds. For each of them task-specific datasets, such as queries, candidate sets, and relevance ground truth’s for the Wikimarks are exported. By default the following information is provided for each dataset:
- Articles †:
Content of processed articles (JSONL or CBOR).
- Titles/QIDs:
Page titles and Wikidata QIDs of pages in this subset.
- Paragraphs †:
Corpus of paragraphs from this article subset.
- Provenance:
Information about the Wikipedia dump the subset originated from.
Additionally, task-specific Wikimark data is provides as described in the following.
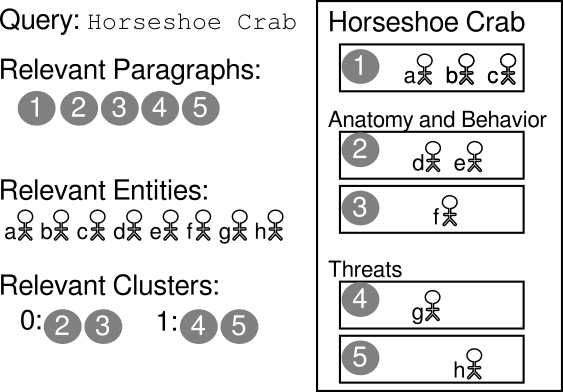
Retrieval Wikimark
The retrieval Wikimark is designed to study the quality of retrieval models. For queries derived from Wikipedia titles, any paragraph originating from the Wikipedia article is counted as relevant. This Wikimark was referred to as the “automatic ground truth” in the TREC Complex Answer Retrieval task.
Wikimarks for three kinds of retrieval scenarios are provided:
Article: The query is the page title, and the goal is to retrieve paragraphs that are relevant for this query. For the passage retrieval relevance data (i.e., qrels) any paragraph located anywhere on the original page is counted as relevant, all other paragraphs are non-relevant.
Toplevel: The query is a combination of page title and heading of a top-level section. The goal is to retrieve paragraphs that are in fact located within this section or one of its subsections.
Hierarchical: The query is derived from any section on the page. The goal is to retrieve paragraphs that are exactly in this section, not a subsection.
In addition to passage-level retrieval, we also provide a Wikimark for entity retrieval, where any entity (as represented by their Wikipedia pages) that is linked to from a relevant paragraph is regarded as relevant.
As a corpus for retrieving passages from, we recommend to use the paragraph corpus. As a legal set of entities, we recommend to use an unprocessed dump of Wikipedia pages.
For the retrieval Wikimark, we provide the following information:
- Outlines:
Title and section outlines of the articles, to derive query texts from. Page metadata is available.
- Topics:
Query IDs for each section—these can also be obtained from the outlines.
- Passage Qrels †:
Trec-evalcompatible qrels files of paragraph IDs for article-level retrieval, top-level section retrieval, and hierarchical section retrieval.- Entity Qrels †:
Trec-evalcompatible qrels files of entity IDs (same as page IDs) for article, top-level section, and hierarchical section retrieval.
Evaluation.
We recommend to use the retrieval evaluation tool trec-eval with option -c using the provided qrels files.
Query-specific Clustering Wikimark
The task of search result clustering, will, given a search query and a ranking of search results, identify query-specific clusters for presentation. We provide a Wikimark dataset for this clustering task, where the query is taken as page title, and each top-level section defines one ground truth cluster. The search results are taken from the article-level retrieval task. To train on this task in isolation from a retrieval system, we suggest to use all passages that originate from this page.
The query-specific clustering Wikimark is provided as a JSONL gzipped file which contains the following information:
- Query:
The query text is derived from the page name; the query ID from the page ID.
- Elements:
List of paragraph IDs contained on the page.
- True Cluster Labels †:
List of true cluster labels for each element. The i’th cluster label is derived from the section ID of the top-level section where the i’th element is located.
- True Cluster Index †:
Projecting the true cluster labels onto integers from 0, 1….
In this Wikimark, we remove instances with less than two clusters.

Query-specific Entity Linking Wikimark
Entity linking is typically discussed as an NLP task that ignores the context of a search query. However when presenting relevant information for a search query, maybe it would be best not to annotate all possible entity links, but instead focus on linking entities that are relevant for the query. Wikimarks allow us to create a query-specific entity linking dataset, as Wikipedia’s editorial policies are to only include hyperlink to pages when the information is relevant for the topic of the article.
The query-specific entity linking Wikimark is provided as a JSONL gzipped file which contains the following information:
- Query:
The query text is derived from the page name; the query ID from the page ID.
- Text-only Paragraph:
The text contents of paragraph (without entities links), to be annotated with entity links.
- True Linked Paragraph †:
The original paragraph (with links) for training and as ground truth.
- True Entity Labels †:
List of entity IDs that should be linked in this paragraph. These are provided as internal PageIDs as well as Wikidata QIDs.
- Acceptable Entity Labels †:
List of acceptable entity IDs that can be linked in this paragraph without penalty. List of entities linked in this paragraph and any previous paragraph. These are provided as internal PageIDs as well as Wikidata QIDs.
We remove instances of paragraphs without any linked entities.
Wikipedia’s editorial policies mandate that entities are only linked once per article. Consequently, entities that are mentioned repeatedly are only linked once. Since the entity linking ground truth is derived from hyperlinks, entity linking predictions would get penalized for linking all these entities. To alleviate this without resorting to heuristics, we collect all entities linked in all preceding paragraphs of an article and exposed them as acceptable entity labels. The entity linking evaluation should only give credit to every entity in true labels, but not penalize entities in acceptable labels.
Wikimark Train/Test Instances
Number of train/test instances for each Wikimark.
| Relevant Passages | Relevant Entities | Clustering Instances | Entity Linking Instances | |||||||||||||
| en | simple | ja | en | simple | ja | en | simple | ja | en | simple | jp | |||||
| vital-articles.test | 44,444 | 7,117 | 12,448 | 159,392 | 20,626 | 38,975 | 521 | 328 | 393 | 64,857 | 9,339 | 23,217 | ||||
| vital-articles.train | 42,008 | 6,845 | 13,330 | 149,609 | 19,401 | 42,357 | 528 | 324 | 440 | 61,984 | 8,663 | 25,743 | ||||
| good-articles.test | 408,454 | 7 | 23,869 | 1429,087 | 47 | 65,031 | 17,088 | 1 | 626 | 777,081 | 8 | 27,903 | ||||
| good-articles.train | 415,034 | 17 | 24,375 | 1465,327 | 87 | 61,050 | 17,362 | 1 | 626 | 789,726 | 39 | 27,538 | ||||
| US-history.test | 83,213 | 176 | – | 206,672 | 405 | – | 4,232 | 6 | – | 169,014 | 210 | – | ||||
| US-history.train | 83,255 | 146 | – | 205,438 | 608 | – | 4,285 | 7 | – | 160,764 | 173 | – | ||||
| horseshoe-crab.train | 21 | 11 | – | 69 | 40 | – | 1 | 1 | – | 44 | 13 | – | ||||
| benchmarkY1.test | 6,554 | 434 | 1,160 | 15,698 | 1,117 | 3,018 | 131 | 23 | 56 | 8,536 | 454 | 1,978 | ||||
| benchmarkY1.train | 5,588 | 449 | 1,396 | 14,744 | 1,273 | 3,440 | 117 | 25 | 60 | 7,258 | 513 | 2,152 | ||||
| car-train-large.train | 9,254,925 | 113,444 | 1496,289 | 19,764,159 | 249,369 | 3,462,123 | 885,014 | 6,918 | 87,012 | 25,423,934 | 185,203 | 3824,333 | ||||
| test200.train | 5,537 | 109 | 335 | 12,345 | 272 | 929 | 188 | 5 | 19 | 9,147 | 135 | 612 |